
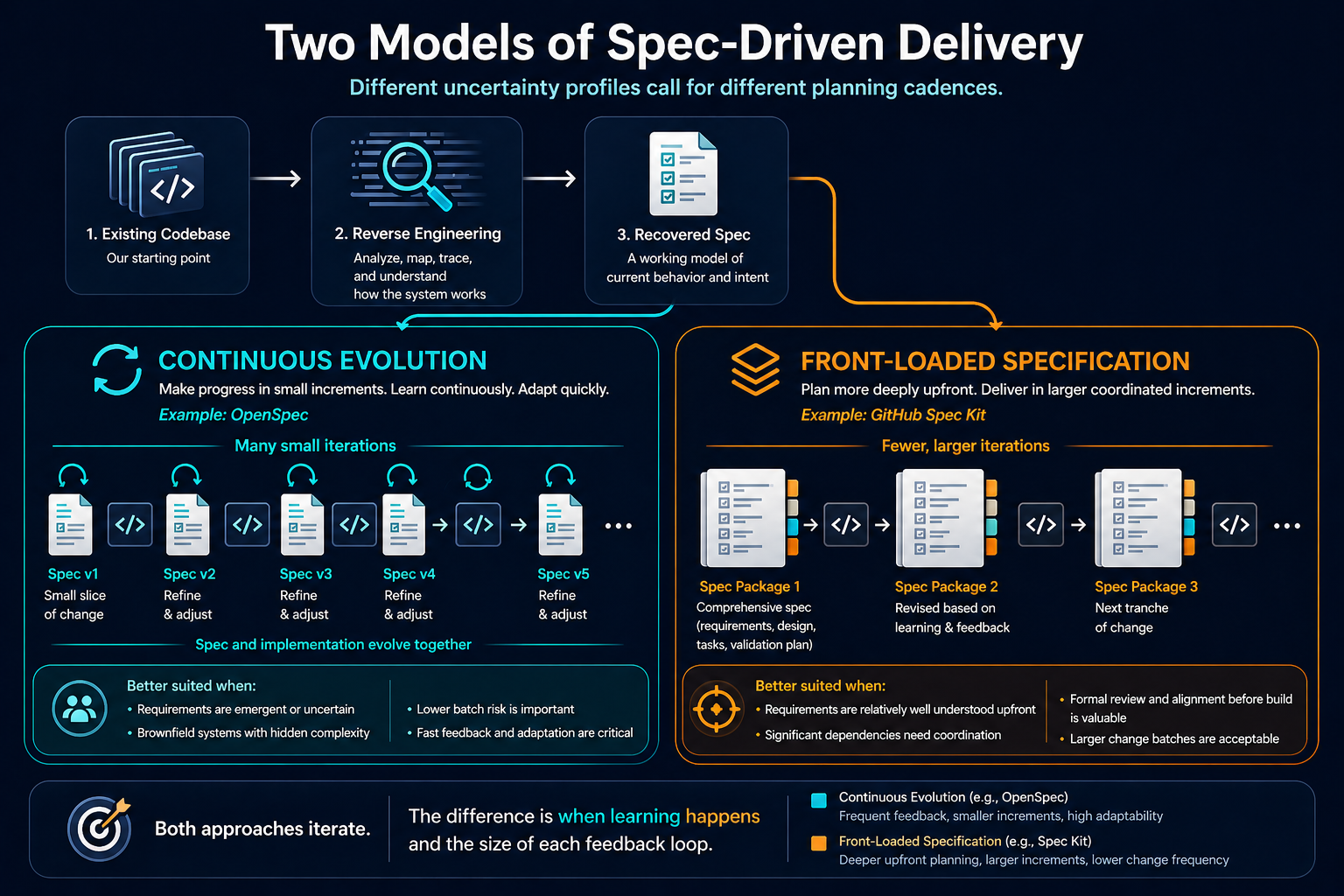
A few days ago I shared a visual on LinkedIn comparing two models of Spec-Driven Development. The two models were continuous evolution and front-loaded specification. The question was simple. Which model do you prefer, and why?
The responses split along predictable lines. Some preferred continuous evolution as a better fit for blurred boundaries between engineering, product, and analysis. Some preferred front-loaded specification for larger teams or stable domains. Some called the choice conditional on the cost of iteration. Underneath all of it, one commenter asked the sharper question. Why bother keeping specs at all, when code and commit messages already document what was built?
That question tracks with pushback I have heard from clients directly. Spec-Driven Development, in the form most often demonstrated, is seen as a PoC pattern. Greenfield. Solo developer. Curated stage. The moment it meets a real codebase, the argument goes, it falls apart and the generated code is sub-standard.
That critique is largely correct, and I want to take it seriously. Most public demonstrations of SDD are shaped to look cleaner than the systems any of us actually work in. A skeptic pattern-matching to “this will not survive my codebase” is reading the evidence accurately.
But they are diagnosing the wrong thing. The methodology is not broken. The discussion of it has flattened into one step. Write a good spec, feed it to the AI, get the output. That is the version the skeptics are seeing, and that version really does fail at scale. The version I am proposing is not one step. It is a system. Five layers, each doing work the others cannot. Take any one away and natural-language spec-driven development does not hold together for serious work.
A Five-Layer System
The model I am proposing has five layers, and each exists because of a specific failure mode the others cannot address.
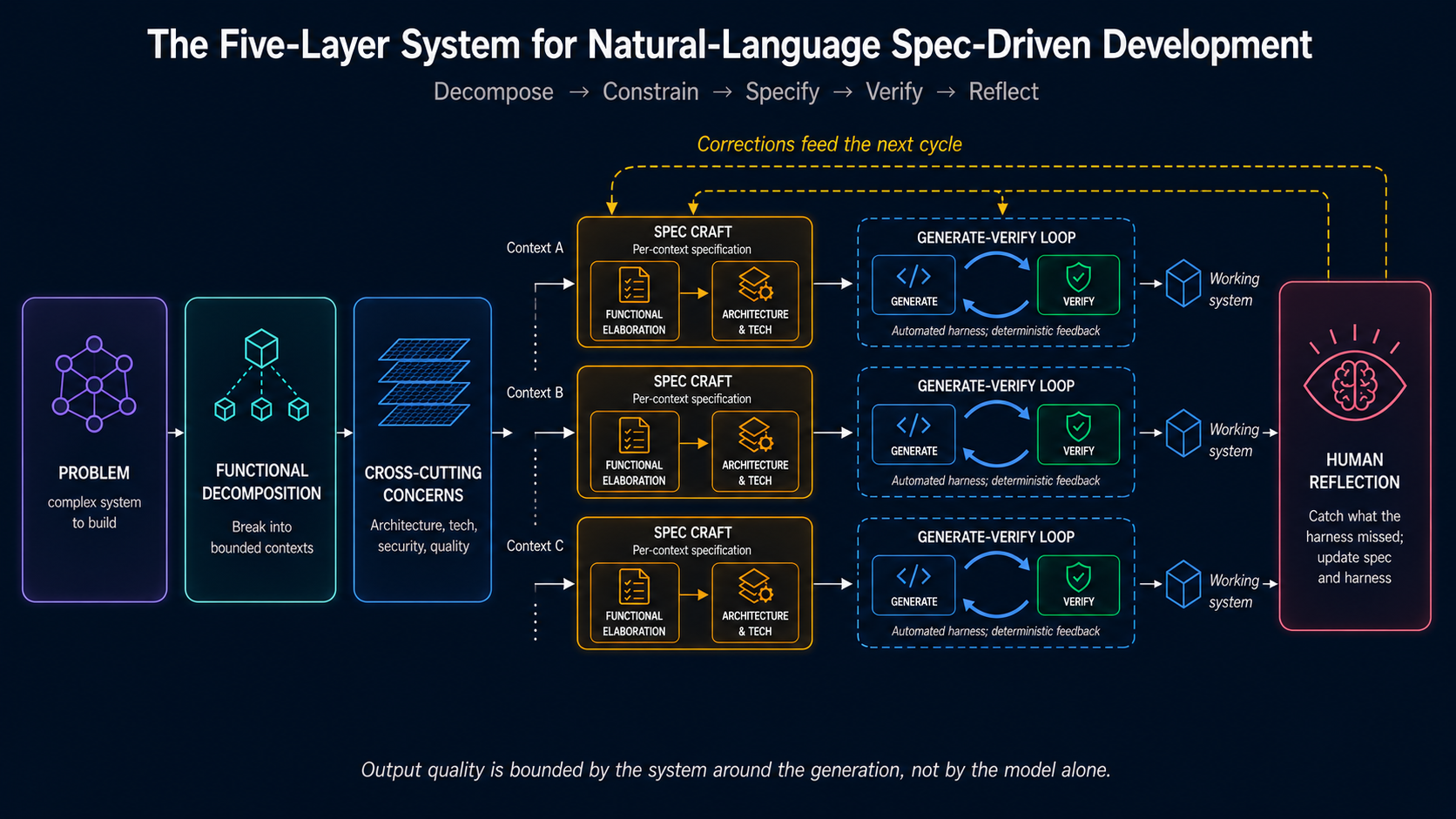
The system starts with functional decomposition, which breaks the problem into bounded contexts. Around and across those contexts sit the cross-cutting concerns, the architectural, platform, security, and quality decisions that would otherwise be reinvented inside each context. With both in place, specification craft elaborates each context, functional intent first and architectural choices second. The automated harness then verifies what gets generated. Human reflection wraps the cycle, catching what slipped through and improving both spec and harness for the next pass.
Two patterns run through this list.
Function before form. Decide what before how, at every level. When breaking the system into contexts, ask what work each must do before deciding the platform or stack. When writing the spec for one context, name the behavior before the architecture. Invert this and the wrong shape gets locked in early, when changing it is most expensive.
The same shape repeats at every level. A bounded context is itself a small system, and so is each part inside it. The five moves recur all the way down. Each level needs its own decomposition, its own settling of what cuts across the parts, its own specs, its own verification, and its own reflection on what slipped. The weight of each layer scales with the work, but the shape does not change. Complexity still needs decomposition. Natural language is still ambiguous. Verification still leaves a residual.
The rest of this post walks through each layer in turn.
Functional Decomposition
The first move is to break the problem into smaller, independent parts with clear ownership, clean contracts, and a scope small enough that a spec can describe each without bleeding into its neighbors.
Most discussions of SDD skip past this. In a demo it looks easy. In a real codebase it is the hardest layer in the system. Brownfield boundaries rarely announce themselves. They are tangled, mis-named, and built up over years of features whose original lines no longer hold. Anyone who hears “decompose into bounded contexts” and thinks “easy for you to say” is right.
One thing to be clear about first. Bounded contexts are logical, not physical. They can live as modules in a monolith, packages with visibility rules, separate schemas in one database, or different teams sharing a codebase. They might become separate services later if that pays off. SDD does not require you to break up your monolith. It requires boundaries clear enough that a spec can describe one without leaking into another.
Three things have made this work easier than it used to be.
The code is already in front of you, and AI makes it readable at scale. Existing systems hold evidence about where the boundaries are. Files that change together in commits usually belong together. A User or Order type that turns up in twenty modules is often two or three contexts pretending to be one. Tables that always join cluster into a context. Tables that never join probably do not. Team ownership and existing anti-corruption layers add more signal. No one can hold a 500-module call graph in their head. Tools like graphify make this evidence usable in minutes rather than weeks.
Experiments are cheap now. Before AI, building three candidate decompositions in code was too expensive. Teams whiteboarded, committed, and found out six months later that the boundary was wrong. Now you can stand up three candidates in an afternoon, stress them against a few real scenarios, and throw two away. This works in greenfield too. Brownfield gives you evidence in the code. Greenfield gives you fewer constraints to fight.
Domain experts catch what AI cannot. AI knows the code. It does not know the business. The codebase uses “Customer” everywhere, but the expert knows “Customer in marketing” and “Customer in billing” are different things that happen to share a table. Where the code and the expert agree, you have a strong candidate. Where they disagree, you have the most valuable signal of the whole exercise. The code drifted from the business. Or the expert is describing a wish, not the reality. Or there is an undocumented constraint nobody surfaced. Pull that thread.
Two pieces of discipline keep this honest. Throwaway experiments have to actually be thrown away. Running code has gravity, and teams that build three prototypes often keep the first one that compiled, not the one that taught them the most. And the scenarios have to be the revealing ones. Happy paths show nothing. Cross-cutting transactions, retries, partial failure, and bulk operations are where weak decompositions break.
So decomposition is not a gate the team passes through before SDD begins. It is the first move in a loop. Code archaeology proposes candidates. Cheap experiments stress them. Experts confirm them. The spec layer commits to one, and when the spec strains, that strain feeds back into the decomposition. AI amplifies whatever shape it is pointed at. With this loop running, the shape gets better with each pass.
Cross-cutting Concerns
Some decisions span every bounded context. Architecture (deployment topology, integration patterns, data flow). Technology choices for what touches the boundaries between contexts (the integration contracts, the runtime platform, the identity provider, the observability stack, the CI/CD pipeline). Quality guidelines (coverage, performance, accessibility, reliability targets). Security posture (authentication, authorization, data handling, compliance). Data strategy.
These are typically owned by specialists who do not write code inside any single context but whose decisions shape what every context must do. Some constraints are inherited (the cloud, the regulatory regime, the existing identity provider) and cannot be deferred. Others are chosen once and applied everywhere.
Not every technology decision is cross-cutting. The contracts between contexts are shared agreements. Every context that participates in a contract must build to the same specification, which is why these decisions are cross-cutting. The internals of each context can vary. The contracts cannot. The language a context is implemented in, the framework it uses, its data store, and its internal architecture can all vary across contexts, as long as the cross-cutting contracts are honored. One context in Java, another in Ruby, another in Rust can all integrate cleanly through agreed contracts. Those choices belong inside specification craft, not here.
With AI-assisted generation, the marginal cost of polyglot has fallen, but so has the reason to deviate. Defaulting to a standard stack across contexts is sensible unless a context has a real reason to differ, such as performance, regulation, or library ecosystem. The AI’s productivity advantage is uneven across languages, and exotic per-context choices erode it.
Without these cross-cutting decisions made explicit, each context invents its own answer and the resulting system cannot integrate without painful retrofit. With them made explicit, each context’s specification has constraints it can take as given.
Specification Craft
A framing note before getting into the work. The two previous layers, functional decomposition and cross-cutting concerns, are prerequisites to spec writing, not specs themselves. They establish the constraints the spec lives within. The better you understand them, the better the spec you can write.
With those constraints in hand, the spec describes what each context must do and how it will be built. Functional elaboration comes first. The spec names behaviors, contracts, invariants, acceptance criteria, and the intent of the system from the domain perspective. Architectural and technology choices for the context come next, made within the cross-cutting constraints already settled.
Specs earn their keep by encoding what code cannot. They record the intent behind decisions made and decisions deliberately not taken, so future work does not have to reconstruct the reasoning by guessing. They are also the artifact non-technical stakeholders (regulators, domain experts, product owners) can validate when they cannot read source.
The spec is an expression of linguistic intent. The harness is its executable contract. The code is the implementation, and it has to agree with both. Three views of the same agreement, each in a different language. The spec captures intent humans can read. The harness captures intent a machine can verify. The code is what actually runs. None of the three is redundant. The spec carries meaning the harness cannot encode. The harness proves conformance the spec cannot. The code is the only one that executes. When two of them disagree, one is wrong. Finding which is the work.
Most importantly, the spec can serve as the regeneration contract. The next iteration of the system may be produced by regenerating against an updated spec rather than by editing the previous code. When that discipline holds, defects, new requirements, and refactors all get expressed at the spec level, and the code becomes downstream output rather than the artifact you protect.
The Harness
The harness is a set of executable expectations. These include static analysis, automated tests, coverage thresholds, mutation testing, contract validation, fitness functions, security gates, etc. Birgitta Böckeler’s Harness engineering for coding agent users treats this layer in depth.
The harness does not reach into generation. It decides what survives generation. In agentic setups, it closes a loop. The agent generates, verifies, regenerates against any failure, and verifies again. The better the harness, the higher the ceiling on what gets through.
Prompts and specs request good behavior. Harnesses make undesirable outcomes hard to ship. The harness is where verification is automated, and automation is what makes the verification scale.
Human Reflection
There will always be a residual. A spec asks for the wrong system. Generated code passes every test but behaves incorrectly in production. An integration assumption slips past the entire test suite. The human’s job is not to verify every output, which does not scale. It is to watch for what the harness missed and feed corrections back upstream. A failure caught in production becomes a new fitness function. A spec that produced misleading code becomes a clearer spec. A pattern of brittle generation becomes a refinement to the prompt or the bounded context.
Reflection appears to sit last in the sequence, but applies at every layer. After every decomposition choice, every cross-cutting decision, every spec change, every harness addition. The discipline is to keep the touches light. SDD’s value comes from speed, and intervening at every step erases that gain. The aim is to step in where the system needs human judgment and let it run where it does not.
This is the layer that improves the system over time. Without it, the same errors recur. With it, every cycle of generation makes the next one more reliable.
Back to the Original Question
I started with one question. Front-loaded specification or continuously evolving? The answer, once the five layers are in place, is that the choice becomes a property of the work, not a team preference. A bounded context with a stable, well-understood domain and high coordination cost calls for front-loaded specification. A context with exploratory work, fast feedback, and emergent requirements calls for continuously evolving specification. Most enterprise systems contain both kinds of work, often within the same system, sometimes within the same context over time.
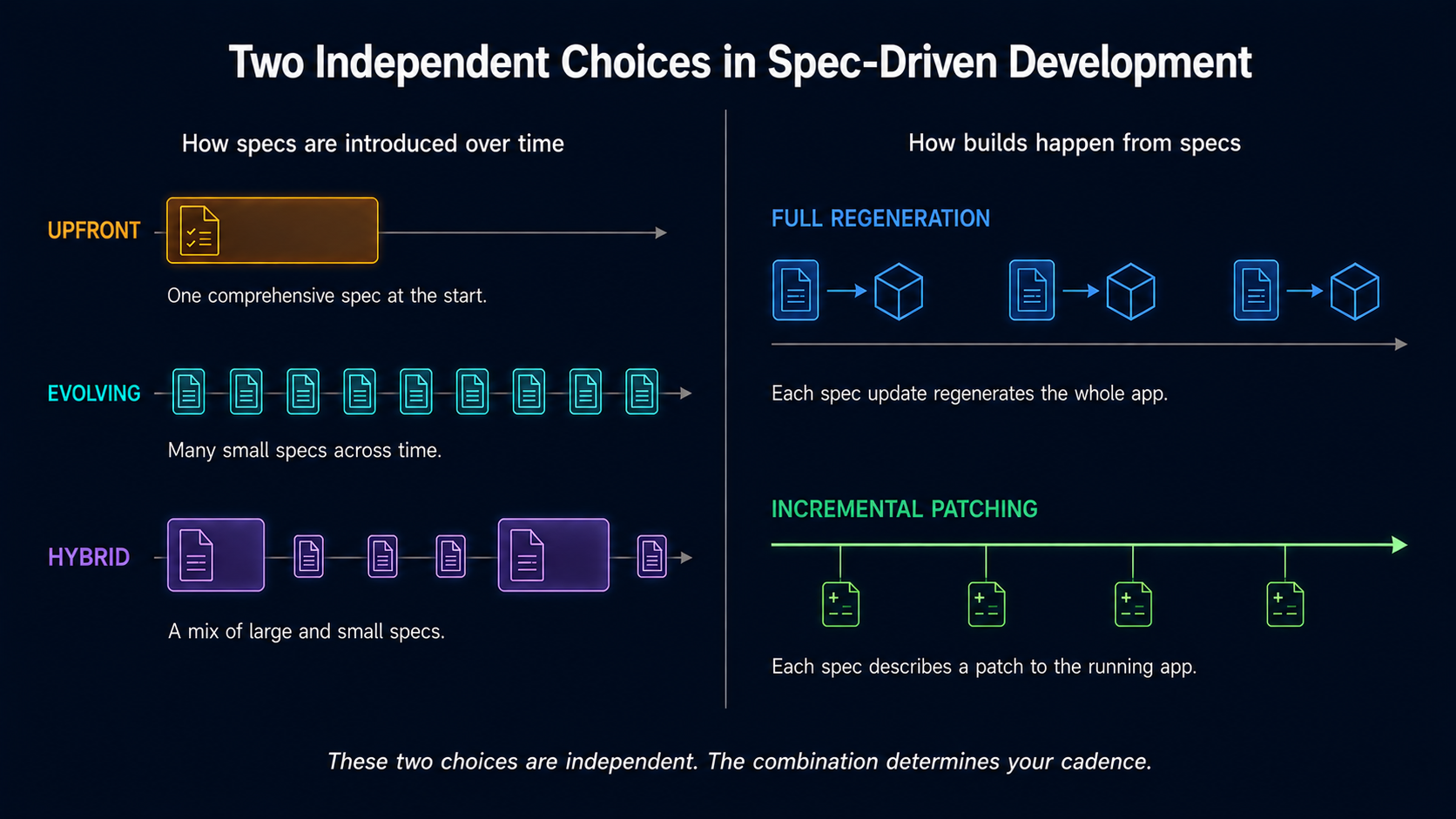
The original LinkedIn debate framed this as a binary choice. It is not. It is a per-context decision, made within a system that supports either mode through the five layers above. The choice is real and matters; it just stops being the central question once the layers are in place.
The System, Not the Spec
The quality of AI-assisted output is bounded by the system around the generation, not by the model alone. Better models help, but they hit a ceiling determined by how well you decomposed, how well the cross-cutting concerns are settled, how well you specified, how rigorous the harness is, and how disciplined the reflection cycle is. PoCs make SDD look easy because the surrounding system is small enough to compensate for sloppy harnesses and rough specs. Enterprise systems do not have that luxury. The surrounding system has to be stronger.
This is the part of Spec-Driven Development that is missing from most of the discussion. The spec is one of five layers, and the other four are doing at least as much work.
These five layers are the ones I keep coming back to. When SDD works at scale, all five are present. When it fails, at least one is missing or underdeveloped. The methodology debates everyone is having (front-loaded versus evolving, OpenSpec versus Spec Kit) are downstream of whether these five layers are in place.
I do not have enough data to claim this model is complete. It is what my experience tells me, and I am proposing it to be tested. If your experience suggests a layer that should not be here, or one that is missing, I want to know.